TEXTOS QUENTES
 018–
IBCI - MODELOS DE ANÁLISE DISCRIMINANTE MÚLTIPLA
E CLUSTERIZAÇÃO ou AGRUPAMENTO: 018–
IBCI - MODELOS DE ANÁLISE DISCRIMINANTE MÚLTIPLA
E CLUSTERIZAÇÃO ou AGRUPAMENTO:
ELEMENTOS FUNDAMENTAIS
Por
Istvan Kasznar - PhD.
istvan@ibci.com.br
Bento Mario Lages Gonçalves, MSc
Consultor Sênior da IBCI
__Esta
seção documental visa apresentar as
mais importantes relações e especificações
técnicas que poderão ser utilizadas,
para a avaliação e a classificação
de dados variados, como por exemplo os oriundos de
municípios e sua tipologia .
__As relações
que seguem mostram sob um ponto de vista estritamente
técnico o arcabouço e a estrutura modelar
que se utiliza para calcular as diversas posições
às quais podem vincular-se variáveis
e gerar múltiplas regressões requisitadas
em casos de se desejar estabelecer elos e vínculos
entre variáveis dependentes e independentes.
__Serão expostas
nesta etapa do trabalho duas metodologias complementares
de cálculo, que visam gerar os resultados,
a sistematização de informações
correlacionáveis e os coeficientes pretendidos,
a saber:
• ADM - Conhecido como o modelo da
Análise Discriminantes Múltipla.
• CLU - Conhecido como o modelo de
Clustering ou de agrupamento.
I - ANALISE DISCRIMINANTE MÚLTIPLA - ADM
__A função
discriminante serve para que se definam e determinem
variáveis discriminantes entre dois ou mais
grupos de dados.
__Eis porque se parte
para um rigoroso e longo processo de identificação,
análise qualitativa e quantitativa, e seleção
operacional básica de dados. Poe exemplo, uma
que estude os dados dos 5.507 municípios do
Brasil, ou que já previamente tenha selecionado
uma amostra representativa de unidades municipais.
É usual fazer-se um corte, e estabelecer uma
afirmativa do tipo “analise-se o grupo dos 1.000
maiores municípios pelo critério da
população total concentrada por município”.
Ou definir-se outro espaço analítico,
como “os maiores municípios são
os que auferem mais renda, logo, é preciso
ordená-los pelo PIB – Produto Interno
Bruto que eles têm, do maior ao menor”.
Ou ainda afirmar que uma variável isolada não
responde bem a um critério de dimensão,
logo o melhor é considerar que “os maiores
municípios são os que apresentam a maior
população; a maior renda; o maior volume
de crédito concedido; o maior volume de depósitos
bancários; o maior volume de impostos pagos;
o maior número de empresas; o maior faturamento;
o maior número de empresários; o maior
número de empregados”, e assim por diante.
__Do ponto de vista
estritamente estatístico, a noção
de “maior” ou de “menor” envolve
questões bem definidas. Permite uma ordenação
técnica, precisa e fria.
__Contudo, em economia
é preciso ir além de classificações
que dão rankeamentos, ordenando do maior ao
menor variáveis que parecem indicar algum poder
econômico.
__O Brasil possui uma
das cinco piores distribuições de renda
do mundo. Esta situação perdura há
cinco séculos.
__Portanto, se, como
é o caso, os 10% mais ricos da população
concentram 47% da renda, existe uma hiperconcentração
de renda e a média estatística de nada
serve. A média pouco indica a verdadeira diáspora
à qual é submetida uma população
majoritariamente miserável.
__Nesse caso, pode
fazer sentido “discriminar” entre os dados,
criando-se segmentos e categorias de dados, assim
como índices prévios, que então
são submetidos a uma classificação.
__Isto significa que
não necessariamente “quem é o
maior é o melhor”. O oposto pode ser
assaz verdadeiro, contudo: “o menor num dado,
pode ser o melhor em muitos outros”. É
preciso analisar mais adequadamente taxas de participação,
correlações e distribuições,
dada uma série e um conjunto de dados.
__Portanto, isoladamente,
o que é relevante não é quem
é o maior, e tem mais”. O que importa
é “quem tendo mais, distribui melhor,
e satisfaz mais”.
__O Brasil se orgulhava
na década de 1980 em ser a “8@ maior
economia do mundo”. Pautado numa única
variável, o Produto Interno Bruto, o país
se esqueceu que “uma andorinha só, não
faz verão”. Ou seja, que uma variável
isolada, fora de um contexto maior, não possui
valor maior.
Em 2003, anunciou-se que o Brasil já possui
a “15@ posição em relação
ao PIB”. Isto é, o país regrediu.
No cenário das nações, foi para
trás.
__Pode haver indicadores
até muito bons. Todavia, o indicador maior,
o mais visível, o que espelha o volume de produção,
esse está se esvaindo.
__Isto não deve
surpreender a nenhum analista bem informado e que
seja sensível com a dimensão sócio
– ética. Ao demolir o planejamento governamental;
ao instituir um Estado em crise permanente e sobredimensionado
em face da capacidade de contribuição
da massa de cidadãos e empresários comuns;
e ao erigir a punição branda a todos
quantos promovem e efetivam crimes contra o Estado
e o erário público, o país construiu
as bases de sua própria implosão de
longo prazo.
__E já se está
há tempos nesse longo prazo.
__Para diminuir os problemas
decorrentes de análises parciais, no plano
internacional não se permite mais o produto
interno bruto de uma nação ser exposto
“à solta”. Pelo contrário,
ele começa a ser associado a renda per capita,
a índices de alfabetização e
a expectativa de vida. Estes três dados formam
o IDH, dito índice de Desenvolvimento Humano.
Apesar de suas falhas e limitações evidentes,
já é bem melhor pois cria associações
que espelham melhor uma sociedade.
__Deste ponto de vista,
o Brasil classificou-se em 2002 no 67º lugar,
quanto ao seu IDH. Isto demonstra cabalmente o quanto
se deve progredir de fato.
__E esta classificação
é oriunda em boa parte de métodos estatísticos,
entre eles, o da ADM.
__A ADM, como instrumento,
permite que se sintam com maior variedade e rigor
mais dimensões e variáveis analíticas,
que correlacionadas, podem oferecer um quadro mais
acurado, mais preciso de uma realidade.
__Eis uma das razões
principais que a leva a ser bastante utilizada pelos
analistas. No lugar de prender-se a uma variável,
como o Brasil fez nas décadas de 1970, 1980
e 1990, amplia-se o espaço analítico
e espectral, o que permite estabelecer elos mais sérios
e justos. Isto legitima melhor as análises
e evita decisões e declarações
apressadas, entre outras vantagens.
__Nas linhas que seguem,
mostra-se um pensamento de ADM relacionado a este
tipo de pensar.
1 - ADM e sua serventia.
__A ADM serve neste caso
para que determinemos quais variáveis podem
ser utilizadas para que sejam as mais representativas
no que se refere à caracterização
de municípios e praças bancárias.
__Neste âmbito,
o grupo interativo do coletou, debateu, selecionou
e verificou (em certos casos ainda em caráter
preliminar), quais variáveis poderiam, em sendo
disponíveis no Banco de Dados, prever melhor
as características de tipos parecidos de grupos.
2 - Aproximação
computacional
__Do ponto de vista
tecnológico e computacional, a ADM é
muito parecida com a análise de variância.
Os modelos tradicionais e já consagrados dos
anos 1960 e 1970, ANOVA e MANOVA, a geram e reproduzem.
__A meta e o conceito
central neste sentido, da ADM, é que se determine
se há diferenciais entre grupos de dados, no
que diz respeito à média de cada variável.
A seguir, procura-se utilizar esta variável
para prever se ela pertence ou não a um grupamento
específico.
3 - Análise de variância
__O questionamento, desafio
e problema que visa ser respondido pelo ADM é
de análise unidirecional de variância
(ANOVA).
__O que se deseja é
saber se dois ou mais grupos são significativamente
diferentes um, do outro, em relação
à média de uma variável específica
pré-estabelecida.
__Caso analisássemos
uma variável apenas, o teste de significância
final que diría se de fato uma variável
discrimina bem entre dois grupos é o teste
de F. Naturalmente, vamos ele pode ser aplicado junto
a outros testes que citaremos mais adiante.
__F é uma razão,
uma proporção da variância entre
grupos em relação a uma taxa média
ponderada de variância intergrupal. Caso a relação
entre estas razões seja pequena, então
a razão entre os dois é significante.
Desta forma, existe pelo menos uma diferença
significativa entre as médias dos grupos.
__Na medida em que
introduzem-se dimensões variadas, surgem múltiplas
opções de cálculo. Num deles,
realizado para uma grande empresa estatal, trabalhou-se
com três dimensões, dadas pelas funções
FUS - DIAT; FUS - DIPE e FUS - DICO. Neste caso, teve-se
uma matriz de variâncias totais e de co-variâncias.
Paralelamente, teve-se uma matriz de variâncias
e covariâncias totais.
__Estas matrizes foram
comparadas por meio de dois testes F multivariados.
Assim, foi possível definir se há diferenças
significativas entre os grupos, em relação
a todas as variáveis das funções
FUS que foram trabalhadas.
__Para definir o procedimento
de corte entre variáveis dependentes e variáveis
independentes nas três dimensões, é
importante entender que neste caso particular em cada
dimensão há indicadores claros que definem
riqueza (força econômica), enquanto outros
dirigem-se à sinalização da pobreza
( ou de carências municipais).
__Desta forma, o corte
ocorrerá em dois níveis, bem claros
e discriminatórios. O que um Governo, uma Secretaria
de Desenvolvimento ou um Banco público deseja
é identificar aonde possui reais formas de
gerar resultados enriquecedores aos acionistas, por
município neste caso, sem perder de vista o
benefício social.
__Este procedimento
é também conhecido como análise
de variância multivariada, ou MANOVA.
4 - Passos na ADM que foi utilizada
__Utilizou-se um modelo
consagrado internacionalmente, o STATISTICA, conhecido
pela sua capacidade de armazenar, processar e processualizar
interativamente um número indefinido (tende
a infinito) de dados.
__Assim, o STATISTICA
analisa cada um dos dados e verifica qual deles contribui
mais ou menos favoravelmente, para a real e efetiva
discriminação entre os grupos. A variável
de maior relevância é então incluída
no modelo, e o sistema eletrônico procede à
etapa seguinte.
__Neste procedimento
de inclusão de variáveis de alto poder
explicativo e de exclusão das de baixo poder
explicativo, são mantidas sempre, evidentemente,
as variáveis mais relevantes. Obviamente, estas
são as que mais discriminam entre os grupos.
__Por exemplo, no caso
de se estabelecer uma política de marketing
bancário, pode ser útil discriminar
entre “municípios pobres” e “municípios
ricos”.
__Os “municípios
ricos” são aqueles que possuem atributos
que se definem como fortemente associados a alta riqueza,
como por exemplo renda alta; renda per-capita alta;
boa distribuição de renda; alta taxa
de crescimento recente e passada do produto; altas
expectativas de crescimento do produto; altos índices
de poupança e investimento; grandes volumes
de depósitos à vista e em fundos; alta
taxa de captação de créditos
baratos, competitivos; significativa concentração
de riqueza; altos índices de produção
em setores de ponta; altos índices de produtividade;
e afins.
__Isto permite então
que com dados variados, se diferenciem grupos e cada
município seja estudado em relação
a si próprio ,e em relação a
um universo maior.
__Mas nem sempre é
possível dispor de tantas variáveis,
que também sejam as mais desejáveis,
como acabamos de citar. Nesse caso, é preciso
verificar com seriedade se o conjunto de dados obtido
possui de fato a capacidade de dar a resposta que
se deseja, pois espelha o que se quer estudar de fato.
__Isto é, as
variáveis independentes possuem altos índices
de correlação com as variáveis
dependentes? E elas são coerentes em sua série
histórica. Dadas as respostas que se estima,
sejam satisfatórias, a estas perguntas, pode-se
avançar na pesquisa.
__Desta forma, por exemplo,
no caso de municípios, praças e logradouros
de baixo "potencial", vistos sob as dimensões
de "atratividade", "complexidade"
e de "perfil", indicarão características
menos interessantes às atividades de banking
mercantil, comercial e de investimento. E vice - versa.
Municípios, praças e logradouros de
alto "potencial", vistos sob as dimensões
de "atratividade", "complexidade"
e de "perfil", indicarão características
mais interessantes às atividades de banking
mercantil, comercial e de investimento.
__Já no caso
de um banco de desenvolvimento, a situação
anterior se inverte e deixa de ter obrigatoriamente
sinalizações “perfeitamente”
corretas. Como é papel de uma instituição
do gênero repassar crédito a taxas subsidiadas
e viabilizar a criação de novos negócios,
novas comunidades que saiam da pobreza para o progresso
e novos espaços onde atualmente existe um vazio,
olhar para os mais ricos, classificá-los e
apoiá-los com mais crédito só
aumentará as diferenças entre ricos
e pobres.
__Então, faz
sentido apoiar com crédito os pobres, para
que eles deixem de ser pobres. Muito embora, possam
argumentar exaustivamente e com boas razões
os diletantes, se percam economias de escala já
geradas em localidades mais ricas; se aumentem os
riscos; e se discrimine contra os mais eficazes e
eficientes. E no mundo globalizado, ajudar o miserável
a sair da miséria e entrar na pobreza é
vital, certamente, lutando-se para que ele salte já
da pobreza à classe média e ao enriquecimento.
Mas este processo custa caro e é demorado.
O justo e essencial capital que vai ao social, em
país pobre que não respeita a poupança
doméstica e sua formação interna
de longo prazo, deixa de irrigar projetos competitivos
locais e os destinados à exportação.
O país deixa de se viabilizar, porque não
tem recursos a aportar ao mesmo tempo a múltiplas
áreas.
__Como fazer o balanceamento?
Aonde alocar os recursos? Aonde há mais chances
de capitalizar municípios, que com rapidez
produzam, possam gerar poupança, e então
com mais recursos puxem os mais miseráveis.
__Ora dirão com
toda razão os mais sócio – orientados:
pobreza não pode esperar. Pobreza tem fome
e é preciso resolver já!
__É verdade.
Faz sentido. Mas ao optar, em políticas públicas
faz-se escolha e política mesmo!
__Naturalmente, o que
seria desejável é dispor de muitos municípios
que tivessem alta atratividade, baixa complexidade
e perfil bem definido. E se fizesse um balanceamento
que catapulta a todos os municípios, oferecendo-lhes
meios de evoluírem no caminho do desenvolvimento.
5 - Análise canônica
__Neste caso particular,
não se necessitará obrigatoriamente
especificar como combinar os grupos. Esta é
uma das vantagens do STATISTICA, que determinará
combinações ótimas previamente.
__A primeira função
proverá o maior índice discriminativo
possível, intergrupal. A segunda função
resultante já oferecerá uma discriminação
intergrupal mais frágil, e assim por diante.
__O importante é
que se evitará a sobreposição
interfuncional, pois as funções serão
ortogonais, logo independentes, umas das outras.
__Neste esquadro, computar-se-ão
tantas funções quantos grupos forem
feitos, menos um. Isto é, operar-se-á
o modelo e o sistema eletrônico com n - 1 graus
de liberdade.
__A percepção
da natureza da discriminação intergrupal
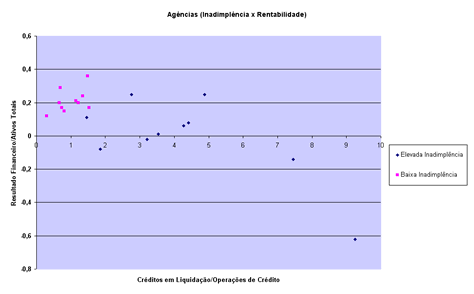
poderá ser gerada visualmente. Analisar-se-ão
as médias das funções entre os
grupos. A seguir, uma plotação de escores
(pontos) das funções discriminantes
permitirá entender como as raízes funcionais
discriminam entre grupos.
6 - Coeficientes de Correlação
__A análise dos
coeficientes de correlação é
outra forma que se utiliza para determinar quais variáveis
definem funções discriminantes específicas.
O fator estrutural resultante, apresentado através
de coeficientes, gera correlações entre
variáveis no modelo e nas funções
discriminantes.
__A importância
desta análise decorre diretamente do fato de
que os coeficientes da função discriminante
apresentam a sua participação específica
e individual, para gerarem a função
discriminante.
7 - Curva e distribuição normal
__Dada a Lei dos Grandes
Números, ao lidar-se por exemplo com 1.027
municípios e seus dados, aproxima-se em diversos
casos de dados distribuídos possívelmente
de forma similar a uma curva normal (curva de Gauss).
__Embora isto nem sempre
ocorra, pois há assimetrías sistemáticas
como as geradas pelo sistema de distribuição
de renda e de PIB no Brasil, é de bom alvitre
utilizar a normalidade na gestão das funções
básicas e iniciais de um modelo. Elas poderão
ser sistematicamente apuradas com a utilização
do STATISTICA.
__Desta forma, é
assumido que os dados das variáveis assumem
uma amostra altamente representativa de uma distribuição
normal multivariada.
__As distribuições
dos dados poderão ser apreciadas mediante a
análise de histogramas, que fornecerão
elementos para verificar se de fato a normalidade
ocorre, ou não.
8 - Classificação
__O propósito
é também o de gerar uma ADM que emita
sinalizações claras acerca de casos
de classificação previsíveis.
__O conceito de pôr
em ordem, de enumerar por pontos recebidos dada a
combinação das variáveis com
os seus respectivos pesos, poderá ser estabelecido.
__Decorrentemente, ao
ser finalizado o modelo ADM verdadeiro, para cada
uma das três dimensões que se pretende
explorar, pode-se responder à questão
mais relevante desta etapa de trabalho: o quão
bem e até que ponto é facultado estabelecer
e prever que um município e uma ou um conjunto
de agências bancárias pertencem a um
grupo específico?
II CLUSTER
9 - Objetivos do Cluster
__O que se pretende ao
organizar dados observados, em estruturas representativas
e significativas de uma realidade, é o desenvolvimento
de categorias, famílias, grupos e portanto
taxonomias.
__O que o método
de clusterização (CLU) faz, é
estabelecer uma sistemática que oferece classificações,
logo agrupamentos. Neste sentido, os membros internos
do grupo obtido possuem entre sí denominadores
comuns de valores.
10 - Elementos do processo de clusterização
Merecem atenção diversos elementos e
passos, num processo CLU, a saber:
1 - juntar dados observados, objetos ou informações,
em clusters cada vez mais amplos e mais agregados;
2 - utilizar alguma medida de similaridade ou de
distância;
3 - associar mais objetos e dados, para agregá-los
por categorias, classes, hierarquias e famílias;
4 - determinar distâncias intergrupais e intragrupais;
5 - a capacidade de interpretar-se o significado
diferenciado de cada cluster gerado, com seus impactos
no processo decisório organizacional;
6 - procurar entender como decorrência, de
que maneira as diferenças, as assimetrias e
as distorções impactam em medidas gerenciais
na organização;
11 - Geração de Amálgamas
__O ato de juntar e de
agrupar permite que se identifiquem fatores de similitude
e de diferença entre grupos diferenciados.
Isto permite que se otimizem políticas empresariais.
__São disponíveis
para os analistas vários métodos de
associar, correlacionar, integrar, misturar ou juntar
dados e de torná-los membros de um grupo. Entre
eles destacam-se os seguintes:
1 - associar dois clusters quando quaisquer dois
dados em dois clusters estão perto um do outro,
minimizando distâncias associativas (single
linkage);
2 - associar os vizinhos de clusters, que apresentam
distâncias significativas entre sí (complete
linkage);
3 - gerar o clustering pelas médias, que
permite que se estipule um valor ou um corte, logo
“se informe” ao sofware, o número
de separações que se considera desejável,
para finalidades previamente e bem estabelecidas.
Neste nível e momento de pesquisas, a busca
por cortes e categorias analíticas é
gerada pela gestão do algoritmo das médias
em número de k, do clustering.
Uma das vantagens deste processo ad-hoc de estabelecimento
de clusters, é o de gerarem-se numerosas (tantas
quantas se desejam), categorias diferenciadoras. Assim,
o atendimento e a compreensão das diferenças
pode ser bem estabelecido.
Na modelagem podem ser por fim utilizados os métodos
livre e estimulado (k) de amalgamação.
Ao longo da modelagem definem-se freqüentemente
em 5 (cinco), os números de cortes a serem
testados.
Deste modo, o analista passa a dispor de uma modelação
básica, que lhe permite evoluir conforme o
seu desejo, a favor de novas descobertas, por exemplo
na área de ciências humanas.
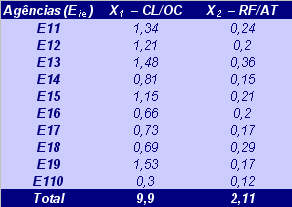
Tabela A.1 – Amostra
da População de Agências com Baixa
Inadimplência (p1)
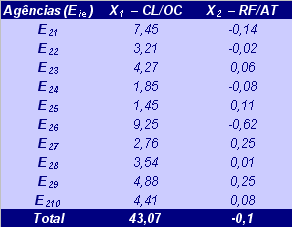
Tabela A.2 –
Amostra da População de Agências
com Elevada Inadimplência (p2)
-
© Copyright IBCI 2002-2007 - All Rights Reserved.
|